

Description:
Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from data in various forms, both structured and unstructured. It is a combination of mathematics, programming, data engineering, and subject matter expertise, used to analyze and interpret data for decision-making and problem-solving.
It encompasses a variety of topics like machine learning (ML), artificial intelligence (AI), natural language processing, data mining, and data visualization. Data scientists use a variety of tools and techniques to extract and analyze data from different sources, such as databases, spreadsheets, and other data sources. These insights are then used to develop models, algorithms, and other predictive models to solve problems and make decisions. Data science is an interdisciplinary field that incorporates elements of computer science, mathematics, statistics, and other fields.
Why Is Data Science Important?
Data science is an increasingly important field in our modern world. It is used to analyze large amounts of data in order to gain useful insights and make informed decisions. Data science is used in a variety of industries, from finance and healthcare to marketing and retail. It is used to identify trends, optimize processes, and create predictive models that can help businesses and organizations make better decisions.
Data science is essential to the success of any business or organization, and its importance is only going to increase in the years ahead. Becoming a data scientist equips you with essential skills for success in the industry and makes you a valuable asset in any organization you find yourself.
Add Video Here: Introduction to machine learning
Important Skills/Subjects that a Data Scientist Must Be Equipped With
1. Programming Languages: A data scientist should be proficient in at least one programming language such as Python, R, Java, or Scala.
2. Machine Learning: Data scientists must have a deep understanding of machine learning algorithms and techniques.
3. Statistics: Knowledge of basic statistics, probability theory, and linear algebra is essential for a data scientist.
4. Data Analysis: A data scientist must be able to analyze large amounts of data and draw meaningful insights from it.
5. Data Visualization: Data scientists must be able to create visualizations and graphs to communicate their findings to stakeholders.
6. Cloud Computing: Experience with cloud computing platforms such as Amazon Web Services and Microsoft Azure is increasingly important for data scientists.
7. Database Management: Knowledge of database management systems such as SQL and NoSQL is essential for a data scientist.
8. Business Acumen: Data scientists must understand the business context and be able to work with stakeholders to provide meaningful insights.
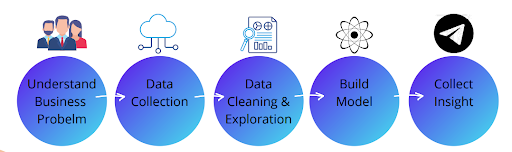
The flow of A Data Science Project
To start with any data science project, you must follow the steps given below:
- Understand the Business Problem: Identify the project goal, target audience, and data needed.
- Acquire the Data: Collect the data from the appropriate sources.
- Clean and Explore the Data: Clean the data from any anomalies and explore the data to gain insights.
- Build the Model: Build and tune different models to solve the problem.
- Collect Insight: Evaluate the performance of the models and interpret the results.
- Deployment: Deploy the model in a production environment.
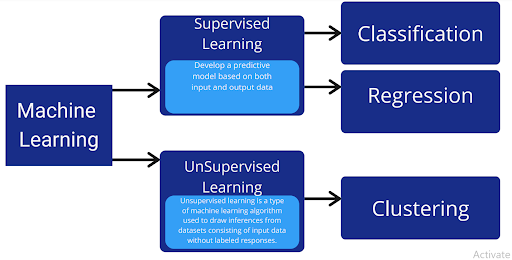
What is Machine Learning?
Machine learning is a subset of Artificial Intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it to learn for themselves.
The learning process begins with observations or data, such as examples, direct experience, or instruction, to look for patterns in data and make better decisions in the future based on the examples we provide. The primary aim is to allow the computers to learn automatically without human intervention or assistance and adjust actions accordingly.
What Are ML Algorithms?
Machine learning algorithms are computer algorithms that learn from data and improve their performance over time without being explicitly programmed. These algorithms can identify patterns in data, detect anomalies, and make predictions. Examples of ML algorithms include decision trees, random forests, support vector machines, and neural networks.
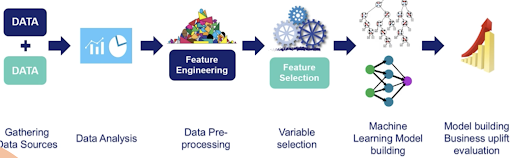
Step for Data Preprocessing
Binarization
Binarization is the process of converting data into a binary format. This is usually done to make data easier to store and process by computers. Binarization involves converting numerical or categorical data into a binary format in which each value is represented as either a 0 or a 1. For instance, a categorical variable with three possible values (e.g., high, medium, low) might be converted into a binary format that would represent each value as either 0 (low), 1 (medium), or 2 (high).
Step 1. Import Num library as a name “np” and import preprocessing function from sklearn.
Step 2. Create a NumPy array for sample data.
Step 3. Binarization Output
To binarize the data, use preprocessing.Binaries(). This function binarizes data according to an imposed threshold. Values greater than the threshold map to 1, while values less than or equal to the threshold map to 0. With the default threshold of 0, only positive values map to 1. In our case, the threshold imposed is 1.4, so values greater than 1.4 are mapped to 1, while values less than 1.4 are mapped to 0.
Output:

(II) Standard Deviation: Standard Deviation is a measure of the spread or dispersion of a set of data values. It is calculated as the square root of the variance of the data. It is used to measure how much variation or dispersion exists from the average (mean) of the data set.
Step 4. Now, find out the mean and standard deviation value for input data.
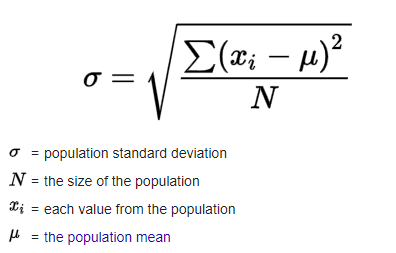
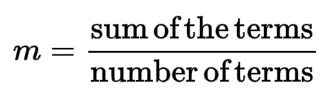
Output:

Mean removal technique
Mean Removal is a data preprocessing technique in Data Science which involves subtracting the mean value from each data point in a dataset. This is done to centre all the data around zero, which can be useful when training a model. The mean value is calculated by taking the average of all data points in the dataset. This technique is useful for removing the mean from our feature vector so that each feature is centered on zero. This is done to remove bias from the features in the feature vector.
Step 5. To do mean removal in input data, use the use scale function.
Output:

Step 6. Now map or scale the values according to the minimum and maximum values of the input data.
Scaling
Data Scaling is a process used to normalize the range of independent variables in order to make sure that the data points can be treated equally. It is also used to bring all the data points to the same level of magnitude which helps in faster processing and better performance of the data models. Scaling helps in many ways such as it avoids bias, improves accuracy, improves convergence speed when training a model, and also makes it easier to compare different data points.
Output:
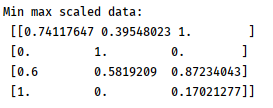
Step 7. Now, use normalization technique to modify the values in the feature vector so that we can measure them on a common scale. In Machine learning, we use many different forms of normalization. Some of the most common forms of normalization aim to modify the values so that they sum up to 1.
Label Encoding: When we perform classification, we usually deal with a lot of labels. These labels can be in the form of words, numbers, or something else. The machine learning functions in sklearn expect them to be numbered. So, if they are already numbers, we can use them directly to start training. But this is not usually the case.
Step 8: Create one list for colors with input_labels variable.
Step 9. Now, map labels into numerical values according to order.
Output:

Step 10. Encode labels values using encoder.transform function.
Output:
![]()
Step 11. Now, inverse these encoded values to label.
Output:
Conclusion:
This tutorial has covered the basics of data pre-processing, from understanding the need for pre-processing to the actual steps in the process. We also discussed some of the common techniques used in data pre-processing. Additionally, this tutorial has discussed the importance of data validation and the process of splitting data into training, validation, and testing sets. By following the steps outlined in this tutorial, data scientists can ensure that their data is clean, accurate, and ready for analysis.

Leave A Comment
Related Posts
Coding is generally considered a boring activity. After all, who wants to sit in front of a computer all day writing in a language that can’t even be read? But that is not all there is to code. It can be used for some really fun coding facts stuff, and there is so much amazing work that you can do only if you knew how to code.
5 Coding Facts That Blow Your Mind
Let us look at five great fun coding facts you might not know about coding.
You Can Make Games With Code
Coding is an umbrella term for the scores of languages and their versions that programmers use to make their applications. We have all played games, on consoles, our mobile phones, or our desktop computers and laptops, at some point in our life. It might not surprise you to know that these games are also created using code. The complex physics of the characters in these games, the design of the environment of the games, and each minute movement in the games have a piece of code behind them.
Game designers typically write in languages such as C++, C#, and Java. These are also some of the most popular kids coding languages, especially for children who like gaming. Coding courses are available widely in all of these languages and the broad domain of game design.
You Do Better At School If You Code
Making games and indulging in the fun applications of coding is all fine, but coding can have great advantages at school as well. Once you start taking classes that teach coding for kids, you will realize that coding requires a lot of brainpower as well. Coding even for the most fun tasks requires you to think quite a bit, and this sharpens your mind and increases your capability to think logically.
This logical capability can be of a lot of use to you at school. Especially in subjects like mathematics, you might find yourself topping the class simply because of the practice you got during coding! In fact, coding and mathematics have a kind of symbiotic relationship – what you learn in maths comes of use in code and vice versa.
You Can Follow Your Interest Using Coding
Regardless of what your favorite subject is, or what fields you are interested in, you will find a use for code everywhere. Be it through developing software, creating an all-new app, making a game, or building a simple utility, you will find that coding facts can be a way to enable you to follow your interests through a different path.
All subjects from science to social studies and from mathematics to philosophy use coding in some way for research or education. Be it sports or music, art or architecture, utilities that are made using code are prevalent in every field that you can think of. Taking simple online coding courses can qualify you and build your interest in creating such utilities.
You Can Predict Future Events Through Code
Did you know that predicting the future is an application of coding! Predictive modeling is a field of programming in which code is used to try and predict what will happen in the future on the basis of events that took place in the past. It uses concepts of artificial intelligence and machine learning to create algorithms that learn the behavior of past data and determine the course of future data.
Predictive modeling is one of the most futuristic applications of code and is used to determine everything from the next movie you will like on Netflix to whether it will rain tomorrow. You can opt for closing classes in machine learning to know more about the field, and create your own utilities to predict the future!
Coding Is Free!
You don’t need any sophisticated apparatus except your laptop for coding. All you need is the will to learn more and follow your interests through code. To learn to code you do not need to go to a special school or have any special capabilities. You can opt for free coding classes for kids which are held completely online and follow a completely hands-off approach in helping kids learn to code. There are also a vast number of coding sites for kids on which they can log in to learn basic coding facts for kids without even having to enroll in a class.
Conclusion
The future is already being written, and it is being written in code. Coding for kids classes can help kids of all ages currently going to school not just learn to code but also to have fun in the process. The above applications of code can be a major stepping stone to build the interest of kids in coding, after which they can hone their interests and new skills on even more advanced applications. A platform such as Learningbix can be an excellent way for you to get started.
Coding is generally considered a boring activity. After all, who wants to sit in front of a computer all day writing in a language that can’t even be read? But that is not all there is to code. It can be used for some really fun coding facts stuff, and there is so much amazing work that you can do only if you knew how to code.
5 Coding Facts That Blow Your Mind
Let us look at five great fun coding facts you might not know about coding.
You Can Make Games With Code
Coding is an umbrella term for the scores of languages and their versions that programmers use to make their applications. We have all played games, on consoles, our mobile phones, or our desktop computers and laptops, at some point in our life. It might not surprise you to know that these games are also created using code. The complex physics of the characters in these games, the design of the environment of the games, and each minute movement in the games have a piece of code behind them.
Game designers typically write in languages such as C++, C#, and Java. These are also some of the most popular kids coding languages, especially for children who like gaming. Coding courses are available widely in all of these languages and the broad domain of game design.
You Do Better At School If You Code
Making games and indulging in the fun applications of coding is all fine, but coding can have great advantages at school as well. Once you start taking classes that teach coding for kids, you will realize that coding requires a lot of brainpower as well. Coding even for the most fun tasks requires you to think quite a bit, and this sharpens your mind and increases your capability to think logically.
This logical capability can be of a lot of use to you at school. Especially in subjects like mathematics, you might find yourself topping the class simply because of the practice you got during coding! In fact, coding and mathematics have a kind of symbiotic relationship – what you learn in maths comes of use in code and vice versa.
You Can Follow Your Interest Using Coding
Regardless of what your favorite subject is, or what fields you are interested in, you will find a use for code everywhere. Be it through developing software, creating an all-new app, making a game, or building a simple utility, you will find that coding facts can be a way to enable you to follow your interests through a different path.
All subjects from science to social studies and from mathematics to philosophy use coding in some way for research or education. Be it sports or music, art or architecture, utilities that are made using code are prevalent in every field that you can think of. Taking simple online coding courses can qualify you and build your interest in creating such utilities.
You Can Predict Future Events Through Code
Did you know that predicting the future is an application of coding! Predictive modeling is a field of programming in which code is used to try and predict what will happen in the future on the basis of events that took place in the past. It uses concepts of artificial intelligence and machine learning to create algorithms that learn the behavior of past data and determine the course of future data.
Predictive modeling is one of the most futuristic applications of code and is used to determine everything from the next movie you will like on Netflix to whether it will rain tomorrow. You can opt for closing classes in machine learning to know more about the field, and create your own utilities to predict the future!
Coding Is Free!
You don’t need any sophisticated apparatus except your laptop for coding. All you need is the will to learn more and follow your interests through code. To learn to code you do not need to go to a special school or have any special capabilities. You can opt for free coding classes for kids which are held completely online and follow a completely hands-off approach in helping kids learn to code. There are also a vast number of coding sites for kids on which they can log in to learn basic coding facts for kids without even having to enroll in a class.
Conclusion
The future is already being written, and it is being written in code. Coding for kids classes can help kids of all ages currently going to school not just learn to code but also to have fun in the process. The above applications of code can be a major stepping stone to build the interest of kids in coding, after which they can hone their interests and new skills on even more advanced applications. A platform such as Learningbix can be an excellent way for you to get started.
Coding is generally considered a boring activity. After all, who wants to sit in front of a computer all day writing in a language that can’t even be read? But that is not all there is to code. It can be used for some really fun coding facts stuff, and there is so much amazing work that you can do only if you knew how to code.
5 Coding Facts That Blow Your Mind
Let us look at five great fun coding facts you might not know about coding.
You Can Make Games With Code
Coding is an umbrella term for the scores of languages and their versions that programmers use to make their applications. We have all played games, on consoles, our mobile phones, or our desktop computers and laptops, at some point in our life. It might not surprise you to know that these games are also created using code. The complex physics of the characters in these games, the design of the environment of the games, and each minute movement in the games have a piece of code behind them.
Game designers typically write in languages such as C++, C#, and Java. These are also some of the most popular kids coding languages, especially for children who like gaming. Coding courses are available widely in all of these languages and the broad domain of game design.
You Do Better At School If You Code
Making games and indulging in the fun applications of coding is all fine, but coding can have great advantages at school as well. Once you start taking classes that teach coding for kids, you will realize that coding requires a lot of brainpower as well. Coding even for the most fun tasks requires you to think quite a bit, and this sharpens your mind and increases your capability to think logically.
This logical capability can be of a lot of use to you at school. Especially in subjects like mathematics, you might find yourself topping the class simply because of the practice you got during coding! In fact, coding and mathematics have a kind of symbiotic relationship – what you learn in maths comes of use in code and vice versa.
You Can Follow Your Interest Using Coding
Regardless of what your favorite subject is, or what fields you are interested in, you will find a use for code everywhere. Be it through developing software, creating an all-new app, making a game, or building a simple utility, you will find that coding facts can be a way to enable you to follow your interests through a different path.
All subjects from science to social studies and from mathematics to philosophy use coding in some way for research or education. Be it sports or music, art or architecture, utilities that are made using code are prevalent in every field that you can think of. Taking simple online coding courses can qualify you and build your interest in creating such utilities.
You Can Predict Future Events Through Code
Did you know that predicting the future is an application of coding! Predictive modeling is a field of programming in which code is used to try and predict what will happen in the future on the basis of events that took place in the past. It uses concepts of artificial intelligence and machine learning to create algorithms that learn the behavior of past data and determine the course of future data.
Predictive modeling is one of the most futuristic applications of code and is used to determine everything from the next movie you will like on Netflix to whether it will rain tomorrow. You can opt for closing classes in machine learning to know more about the field, and create your own utilities to predict the future!
Coding Is Free!
You don’t need any sophisticated apparatus except your laptop for coding. All you need is the will to learn more and follow your interests through code. To learn to code you do not need to go to a special school or have any special capabilities. You can opt for free coding classes for kids which are held completely online and follow a completely hands-off approach in helping kids learn to code. There are also a vast number of coding sites for kids on which they can log in to learn basic coding facts for kids without even having to enroll in a class.
Conclusion
The future is already being written, and it is being written in code. Coding for kids classes can help kids of all ages currently going to school not just learn to code but also to have fun in the process. The above applications of code can be a major stepping stone to build the interest of kids in coding, after which they can hone their interests and new skills on even more advanced applications. A platform such as Learningbix can be an excellent way for you to get started.