


If you’re looking to implement natural language processing with Python projects, this step-by-step guide is perfect for you.
Description:-
Smart Virtual Assistant can be used for creating virtual chatbots that can help automate customer service, provide product and service recommendations, provide personalized customer service, and respond to inquiries and customer requests. Smart Virtual Assistant can be used to create a virtual assistant that can be used to help customers with their questions and inquiries. The virtual assistant can provide answers to customer queries, provide recommendations and offer personalized support. It can also be used to create intelligent assistants that can be used to automate tasks such as scheduling appointments, tracking customer orders and providing customer support.
Virtual Chatbot
A virtual chatbot is an artificial intelligence (AI) program that is designed to simulate an intelligent conversation with one or more human users via auditory or textual methods. Virtual Chatbots are often used in dialog systems for various practical purposes including customer service or information acquisition. Some chatbots use complex natural language processing systems, but simpler NLP systems scan keywords within the input, then pull a reply with the most matching keywords, or the most similar wording pattern, from a database.
Virtual Assistant
AI virtual assistant, commonly known as AI assistant or digital assistant is an artificial
intelligence (AI) program that can understand and interpret user voice commands to perform
various tasks. AI assistants can help users with a variety of tasks and activities, like scheduling
appointments, setting reminders, playing music, sending emails, and more. AI assistants are
becoming increasingly popular due to their ability to automate many mundane tasks and make
life easier for users.
Natural language processing (NLP)
Natural language processing (NLP) is an area of computer science, artificial intelligence, and linguistics concerned with the interactions between computers and human (natural) languages. NLP techniques are used to analyze and understand natural language, and to make computers more capable of responding to human communication. It can involve the use of text analytics, machine learning, and natural language understanding to identify and extract meaningful insights from large amounts of unstructured data.
Python and the Natural Language Toolkit (NLTK) are a powerful combination for natural language processing (NLP). NLTK is a suite of open-source libraries and programs for symbolic and statistical natural language processing (NLP) for English, written in the Python programming language. NLTK is useful for a wide range of tasks, such as tokenizing, part-of-speech tagging, parsing, and semantic analysis. It also provides interfaces to various corpora and lexical resources such as WordNet.
NLTK can be used to automate many tasks in natural language processing. For example, it can be used to identify and classify text into different categories, such as sentiment analysis, language identification, and topic modeling. It can also be used to build text summarization systems and text-based search engines. NLTK also provides a wide range of tools for creating and manipulating language data, such as a tokenizer, stemmer, and lemmatizer.
Python is a powerful general-purpose programming language and is widely used for a variety of tasks. It is a great language for developing applications, such as web and mobile applications, as well as for scripting and automation. As such, Python is a natural choice for working
Stepwise Guide to Natural Language Processing with Python
Step 1. Install NLTK (Natural Language Toolkit) for pre-processing the given data.
Step 2. Import all the necessary libraries.
Note: Download nltk data using “nltk.download()” command in the terminal box.
Tokenization: Tokenization in NLP is the process of breaking a piece of text into smaller pieces called tokens. These tokens can be words, phrases, symbols, or even whole sentences. Tokenization is an essential part of almost any NLP task.
Tokenization helps in analyzing the structure of a sentence and is used in a variety of tasks such as sentiment analysis, text classification, text similarity and so on. Before processing the text in NLTK Python tutorial, tokenize it. Split it into smaller parts such as paragraphs to sentences, sentences to words.
Step 3. Define a sample sentence and tokenize this sentence with the tokenization function of nltk.
Step 4. Find out Stop Words in the English Language.
Step 5. Now, filter ’Stop Words’ from the sample sentences.
#Alternative Way:
Output:-
Stemming:-
Stemming in natural language processing (NLP) is the process of reducing inflected (or sometimes derived) words to their word stem, base or root form. The stem need not be identical to the morphological root of the word; it is usually sufficient that related words map to the same stem, even if this stem is not in itself a valid root. Stemming is important in natural language understanding (NLU) and natural language search.
Step 6: Import Porterstemmer from nltk. The stem also defines as a porter stemmer.
Step 7: Define an array of the similar kind of words. Also, find stemming words for these example word with stem function of nltk.
Output :-
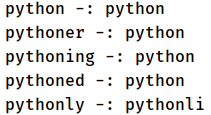
Conclusion :-
Natural Language Processing (NPL) with Python is a powerful and popular tool for extracting meaningful information from text. This step-by-step guide has provided a comprehensive overview of the essential steps for working with natural language processing using Python. From understanding the fundamentals of Python programming to using libraries and frameworks to build NLP projects, this guide has shown how to get started with natural language processing. With a little practice and dedication, you can use Python to make sense of the text and develop powerful applications.
You can read – An Introduction to Data Science and Data Pre-Processing

Leave A Comment
Related Posts
Coding is generally considered a boring activity. After all, who wants to sit in front of a computer all day writing in a language that can’t even be read? But that is not all there is to code. It can be used for some really fun coding facts stuff, and there is so much amazing work that you can do only if you knew how to code.
5 Coding Facts That Blow Your Mind
Let us look at five great fun coding facts you might not know about coding.
You Can Make Games With Code
Coding is an umbrella term for the scores of languages and their versions that programmers use to make their applications. We have all played games, on consoles, our mobile phones, or our desktop computers and laptops, at some point in our life. It might not surprise you to know that these games are also created using code. The complex physics of the characters in these games, the design of the environment of the games, and each minute movement in the games have a piece of code behind them.
Game designers typically write in languages such as C++, C#, and Java. These are also some of the most popular kids coding languages, especially for children who like gaming. Coding courses are available widely in all of these languages and the broad domain of game design.
You Do Better At School If You Code
Making games and indulging in the fun applications of coding is all fine, but coding can have great advantages at school as well. Once you start taking classes that teach coding for kids, you will realize that coding requires a lot of brainpower as well. Coding even for the most fun tasks requires you to think quite a bit, and this sharpens your mind and increases your capability to think logically.
This logical capability can be of a lot of use to you at school. Especially in subjects like mathematics, you might find yourself topping the class simply because of the practice you got during coding! In fact, coding and mathematics have a kind of symbiotic relationship – what you learn in maths comes of use in code and vice versa.
You Can Follow Your Interest Using Coding
Regardless of what your favorite subject is, or what fields you are interested in, you will find a use for code everywhere. Be it through developing software, creating an all-new app, making a game, or building a simple utility, you will find that coding facts can be a way to enable you to follow your interests through a different path.
All subjects from science to social studies and from mathematics to philosophy use coding in some way for research or education. Be it sports or music, art or architecture, utilities that are made using code are prevalent in every field that you can think of. Taking simple online coding courses can qualify you and build your interest in creating such utilities.
You Can Predict Future Events Through Code
Did you know that predicting the future is an application of coding! Predictive modeling is a field of programming in which code is used to try and predict what will happen in the future on the basis of events that took place in the past. It uses concepts of artificial intelligence and machine learning to create algorithms that learn the behavior of past data and determine the course of future data.
Predictive modeling is one of the most futuristic applications of code and is used to determine everything from the next movie you will like on Netflix to whether it will rain tomorrow. You can opt for closing classes in machine learning to know more about the field, and create your own utilities to predict the future!
Coding Is Free!
You don’t need any sophisticated apparatus except your laptop for coding. All you need is the will to learn more and follow your interests through code. To learn to code you do not need to go to a special school or have any special capabilities. You can opt for free coding classes for kids which are held completely online and follow a completely hands-off approach in helping kids learn to code. There are also a vast number of coding sites for kids on which they can log in to learn basic coding facts for kids without even having to enroll in a class.
Conclusion
The future is already being written, and it is being written in code. Coding for kids classes can help kids of all ages currently going to school not just learn to code but also to have fun in the process. The above applications of code can be a major stepping stone to build the interest of kids in coding, after which they can hone their interests and new skills on even more advanced applications. A platform such as Learningbix can be an excellent way for you to get started.
Coding is generally considered a boring activity. After all, who wants to sit in front of a computer all day writing in a language that can’t even be read? But that is not all there is to code. It can be used for some really fun coding facts stuff, and there is so much amazing work that you can do only if you knew how to code.
5 Coding Facts That Blow Your Mind
Let us look at five great fun coding facts you might not know about coding.
You Can Make Games With Code
Coding is an umbrella term for the scores of languages and their versions that programmers use to make their applications. We have all played games, on consoles, our mobile phones, or our desktop computers and laptops, at some point in our life. It might not surprise you to know that these games are also created using code. The complex physics of the characters in these games, the design of the environment of the games, and each minute movement in the games have a piece of code behind them.
Game designers typically write in languages such as C++, C#, and Java. These are also some of the most popular kids coding languages, especially for children who like gaming. Coding courses are available widely in all of these languages and the broad domain of game design.
You Do Better At School If You Code
Making games and indulging in the fun applications of coding is all fine, but coding can have great advantages at school as well. Once you start taking classes that teach coding for kids, you will realize that coding requires a lot of brainpower as well. Coding even for the most fun tasks requires you to think quite a bit, and this sharpens your mind and increases your capability to think logically.
This logical capability can be of a lot of use to you at school. Especially in subjects like mathematics, you might find yourself topping the class simply because of the practice you got during coding! In fact, coding and mathematics have a kind of symbiotic relationship – what you learn in maths comes of use in code and vice versa.
You Can Follow Your Interest Using Coding
Regardless of what your favorite subject is, or what fields you are interested in, you will find a use for code everywhere. Be it through developing software, creating an all-new app, making a game, or building a simple utility, you will find that coding facts can be a way to enable you to follow your interests through a different path.
All subjects from science to social studies and from mathematics to philosophy use coding in some way for research or education. Be it sports or music, art or architecture, utilities that are made using code are prevalent in every field that you can think of. Taking simple online coding courses can qualify you and build your interest in creating such utilities.
You Can Predict Future Events Through Code
Did you know that predicting the future is an application of coding! Predictive modeling is a field of programming in which code is used to try and predict what will happen in the future on the basis of events that took place in the past. It uses concepts of artificial intelligence and machine learning to create algorithms that learn the behavior of past data and determine the course of future data.
Predictive modeling is one of the most futuristic applications of code and is used to determine everything from the next movie you will like on Netflix to whether it will rain tomorrow. You can opt for closing classes in machine learning to know more about the field, and create your own utilities to predict the future!
Coding Is Free!
You don’t need any sophisticated apparatus except your laptop for coding. All you need is the will to learn more and follow your interests through code. To learn to code you do not need to go to a special school or have any special capabilities. You can opt for free coding classes for kids which are held completely online and follow a completely hands-off approach in helping kids learn to code. There are also a vast number of coding sites for kids on which they can log in to learn basic coding facts for kids without even having to enroll in a class.
Conclusion
The future is already being written, and it is being written in code. Coding for kids classes can help kids of all ages currently going to school not just learn to code but also to have fun in the process. The above applications of code can be a major stepping stone to build the interest of kids in coding, after which they can hone their interests and new skills on even more advanced applications. A platform such as Learningbix can be an excellent way for you to get started.
Coding is generally considered a boring activity. After all, who wants to sit in front of a computer all day writing in a language that can’t even be read? But that is not all there is to code. It can be used for some really fun coding facts stuff, and there is so much amazing work that you can do only if you knew how to code.
5 Coding Facts That Blow Your Mind
Let us look at five great fun coding facts you might not know about coding.
You Can Make Games With Code
Coding is an umbrella term for the scores of languages and their versions that programmers use to make their applications. We have all played games, on consoles, our mobile phones, or our desktop computers and laptops, at some point in our life. It might not surprise you to know that these games are also created using code. The complex physics of the characters in these games, the design of the environment of the games, and each minute movement in the games have a piece of code behind them.
Game designers typically write in languages such as C++, C#, and Java. These are also some of the most popular kids coding languages, especially for children who like gaming. Coding courses are available widely in all of these languages and the broad domain of game design.
You Do Better At School If You Code
Making games and indulging in the fun applications of coding is all fine, but coding can have great advantages at school as well. Once you start taking classes that teach coding for kids, you will realize that coding requires a lot of brainpower as well. Coding even for the most fun tasks requires you to think quite a bit, and this sharpens your mind and increases your capability to think logically.
This logical capability can be of a lot of use to you at school. Especially in subjects like mathematics, you might find yourself topping the class simply because of the practice you got during coding! In fact, coding and mathematics have a kind of symbiotic relationship – what you learn in maths comes of use in code and vice versa.
You Can Follow Your Interest Using Coding
Regardless of what your favorite subject is, or what fields you are interested in, you will find a use for code everywhere. Be it through developing software, creating an all-new app, making a game, or building a simple utility, you will find that coding facts can be a way to enable you to follow your interests through a different path.
All subjects from science to social studies and from mathematics to philosophy use coding in some way for research or education. Be it sports or music, art or architecture, utilities that are made using code are prevalent in every field that you can think of. Taking simple online coding courses can qualify you and build your interest in creating such utilities.
You Can Predict Future Events Through Code
Did you know that predicting the future is an application of coding! Predictive modeling is a field of programming in which code is used to try and predict what will happen in the future on the basis of events that took place in the past. It uses concepts of artificial intelligence and machine learning to create algorithms that learn the behavior of past data and determine the course of future data.
Predictive modeling is one of the most futuristic applications of code and is used to determine everything from the next movie you will like on Netflix to whether it will rain tomorrow. You can opt for closing classes in machine learning to know more about the field, and create your own utilities to predict the future!
Coding Is Free!
You don’t need any sophisticated apparatus except your laptop for coding. All you need is the will to learn more and follow your interests through code. To learn to code you do not need to go to a special school or have any special capabilities. You can opt for free coding classes for kids which are held completely online and follow a completely hands-off approach in helping kids learn to code. There are also a vast number of coding sites for kids on which they can log in to learn basic coding facts for kids without even having to enroll in a class.
Conclusion
The future is already being written, and it is being written in code. Coding for kids classes can help kids of all ages currently going to school not just learn to code but also to have fun in the process. The above applications of code can be a major stepping stone to build the interest of kids in coding, after which they can hone their interests and new skills on even more advanced applications. A platform such as Learningbix can be an excellent way for you to get started.